2. Frbr-classes (works) file format
3.3. “Hierarchical Agglomerative Clustering – HAC” Algorithm
3.4. “BiSecting K-Μeans” Algorithm
4. XML attribute: “inter_cluster_sim” (Similarity between clusters)
5. XML attribute: “similarity_method”
frbrCluster
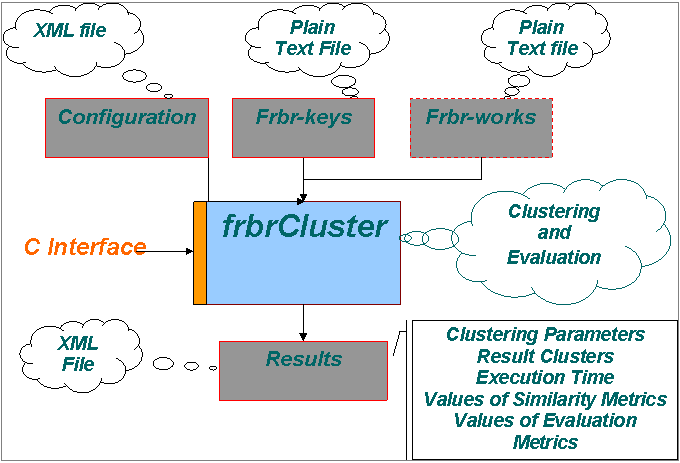
1. Frbr-keys file format
Frbr-keys are portions of bibliographic records that used for FRBR-Work identification. The file that contains such keys must have the format:
sub-key pair [white-character] sub-key pair [white-character] . . .etc [new-line]
where, sub-key pair = sub-key name [white-character] sub-key value.
See below [2] for an example.
2. Frbr-classes (works) file format
|
#line |
Frbr-keys file |
Frbr-classes file |
Remarks |
|
1 |
author SHAKESPEARE WILLIAM title AS YOU LIKE IT |
1 2 |
Frbr-key_1 (line 1) and frbr-key_2 (line 2) of the file “frbr-keys” refers to the same FRBR work. So these line numbers exists to the same line into classes file. |
|
2 |
author SHAKESPEARE WILLIAM title AS YOU LIKE IT |
3 4 5 |
Frbr-key_3 (line 3), Frbr-key_4 (line 4) and frbr-key_5 (line 5) of the file “frbr-keys” refers to the same FRBR work. So these line numbers exists to the same line into classes file. |
|
3 |
author SHAKESPEARE WILLIAM title HAMLET |
6 7 10 11 |
. . . |
|
4 |
author SHAKESPEARE WILLIAM title HAMLET |
8 9 12 |
. . . |
|
5 |
author SHAKESPEARE WILLIAM title HAMLET PRINCE OF DENMARK |
|
|
|
6 |
author SHAKESPEARE WILLIAM title OTHELLO |
|
|
|
7 |
author SHAKESPEARE WILLIAM title OTHELLO |
|
|
|
8 |
author SHAKESPEARE WILLIAM title THE TRAGEDY OF OTHELLO |
|
|
|
9 |
author SHAKESPEARE WILLIAM title TRAGEDY OF OTHELLO |
|
|
|
10 |
author SHAKESPEARE WILLIAM title OTHELLO |
|
|
|
11 |
author SHAKESPEARE WILLIAM title OTHELLO |
|
|
|
12 |
author SHAKESPEARE WILLIAM title THE TRAGEDY OF OTHELLO THE MOOR OF VENICE |
|
|
3. Configuration File Format
|
<clustering_algorithm name="" check_all="" inter_cluster_sim="" incremental="" step="" print_step_results=""/>
<mergekeys> <mergekey name=""> <similarity_computation doc_vector_values="" similarity_method="" similarity_threshold="" similarity_threshold_upper="" similarity_threshold_step=""/> </mergekey> . . . </mergekeys> </psclustering> |
3.1. “Matching” Algorithm
|
XML element |
XML attribute |
Valid values |
|
clustering_algorithm |
name |
"matching" |
|
mergekey |
name |
e.g. "author" |
3.2. “Single Pass” Algorithm
|
XML element |
XML attribute |
Valid values |
Remarks |
|
clustering_algorithm |
name |
"Single Pass" |
|
|
|
inter_cluster_sim |
"single-link" or "complete-link" or "average-link" |
Mandatory only if similarity_method = "jaro-winkler" |
|
|
incremental |
"yes" or "no" |
|
|
|
step |
e.g. 20 (Each time cluster 20 keys until end.) |
Mandatory only if incremental="yes" |
|
|
print_step_results |
"yes" or "no" |
Print Intermediate clustering results. Mandatory only if incremental="yes". |
|
mergekey |
name |
e.g. "author" |
|
|
similarity_computation |
doc_vector_values |
"none" or "term occurrences" or "term frequency" or "tfidf" |
Method for the computation of the document vectors values. Ignored in the case of "jaro-winkler" similarity metric. |
|
|
similarity_method |
"matching" or "cosine" or "dice" or "dice2" or "jaccard" or "jaro-winkler" or "euclidean" |
Similarity metric |
|
|
similarity_threshold |
e.g. "0.7" (=70% similarity) |
|
|
|
similarity_threshold_upper |
e.g. "0.95" |
End value of the similarity threshold when exist similarity_threshold_step. In this case the clustering is performing many times (start value=similarity_threshold, end value= similarity_threshold_upper, with step=step) |
|
|
similarity_threshold_step |
e.g. "0.05" |
|
3.3. “Hierarchical Agglomerative Clustering – HAC” Algorithm
|
XML element |
XML attribute |
Valid values |
Remarks |
||
|
clustering_algorithm |
name |
"hac" |
|
||
|
|
inter_cluster_sim |
"single-link" or "complete-link" or "average-link" |
|
||
|
|
incremental |
"yes" or "no" |
|
||
|
|
step |
e.g. 20 (Each time cluster 20 keys until end.) |
Mandatory only if incremental="yes" |
||
|
|
print_step_results |
"yes" or "no" |
Print intermediate clustering results. Mandatory only if incremental="yes". |
||
|
mergekey |
name |
e.g. "author" |
|
||
|
similarity_computation |
doc_vector_values |
"none" or "term occurrences" or "term frequency" or "tfidf" |
Method for the computation of the document vectors values. Ignored in the case of "jaro-winkler" similarity metric. |
||
|
|
similarity_method |
"matching" or "cosine" or "dice" or "dice2" or "jaccard" or "jaro-winkler" or "euclidean" |
Similarity metric |
||
|
|
similarity_threshold |
e.g. "0.7" (=70% similarity) |
|
||
|
|
similarity_threshold_upper |
e.g. "0.95" |
End value of the similarity threshold when exist similarity_threshold_step. In this case the clustering is performing many times (start value=similarity_threshold, end value= similarity_threshold_upper, with step=step) |
||
|
|
similarity_threshold_step |
e.g. "0.05" |
|
||
3.4. “BiSecting K-Μeans” Algorithm
|
XML element |
XML attribute |
Valid values |
Remarks |
||
|
clustering_algorithm |
name |
"bisecting K-Μeans" |
|
||
|
|
Check_all |
"single-link" or "complete-link" or "average-link" |
|
||
|
|
inter_cluster_sim |
"single-link" or "complete-link" or "average-link" |
|
||
|
|
incremental |
"yes" or "no" |
|
||
|
|
cluster_center_point |
"arithmetic-mean" or "median" |
|
||
|
|
clustering_times |
e.g. 10 |
|
||
|
|
step |
e.g. 20 (Each time cluster 20 keys until end.) |
Mandatory only if incremental="yes" |
||
|
|
print_step_results |
"yes" or "no" |
Print intermediate clustering results. Mandatory only if incremental="yes". |
||
|
mergekey |
name |
e.g. "author" |
|
||
|
similarity_computation |
doc_vector_values |
"none" or "term occurrences" or "term frequency" or "tfidf" |
Method for the computation of the document vectors values. Ignored in the case of "jaro-winkler" similarity metric. |
||
|
|
similarity_method |
"matching" or "cosine" or "dice" or "dice2" or "jaccard" "jaro-winkler" or "euclidean" |
Similarity metric |
||
|
|
similarity_threshold |
e.g. "0.7" (=70% similarity) |
|
||
|
|
similarity_threshold_upper |
e.g. "0.95" |
End value of the similarity threshold when exist similarity_threshold_step. In this case the clustering is performing many times (start value=similarity_threshold, end value= similarity_threshold_upper, with step=step) |
||
|
|
similarity_threshold_step |
e.g. "0.05" |
|
||
4. XML attribute: “inter_cluster_sim” (Similarity between clusters)
5. XML attribute: “similarity_method”
|
Value |
Similarity Method[1] |
Description |
|
“matching” |
Matching |
Absolute matching |
|
“cosine” |
Cosine similarity |
cos (d1, d2) = (d1 ● d2) / (||d1|| ||d2||) |
|
“dice” |
Dice’s coefficient |
dice (d1, d2) = [ 2 * (d1 ∩ d2) ] / (||d1||+ ||d2||) |
|
“dice2” |
Dice’s coefficient with bigrams |
Dice2 (s, t) = 2 * nt / (n1 + n2)
|
|
“jaccard” |
Jaccard similarity |
jaccard (d1, d2) = (d1 ∩ d2) / (d1 U d2)
|
|
“jaro-winkler” |
Jaro-Winkler similarity |
JaroWinkler(s, t) = Jaro(s, t) + (prefixLength* PREFIXSCALE * (1 - Jaro(s, t))),
Jaro(s, t) = 1/3 [|s’|/ |s| + |t’|/ |t| + (|s’|-Ts’,t’) / 2|s’| ] |
|
“euclidean” |
Euclidean distance |
euclidean (d1, d2) = √[ (d11- d21)2 + ( d12- d22)2 + … + ( d1n- d2n)2 ] |
|
d1: document1 vector (d11, d12, . . . , d1n) d2: document1 vector (d21, d22, . . . , d2n) d1 ● d2 : dot product ||d1|| and ||d2||: vector magnitude Bigrams of a string: all the consecutive character pairs nt: number of common bigrams for two documents n1: number of bigrams of the 1st document n2: number of bigrams for the 2nd document |
||
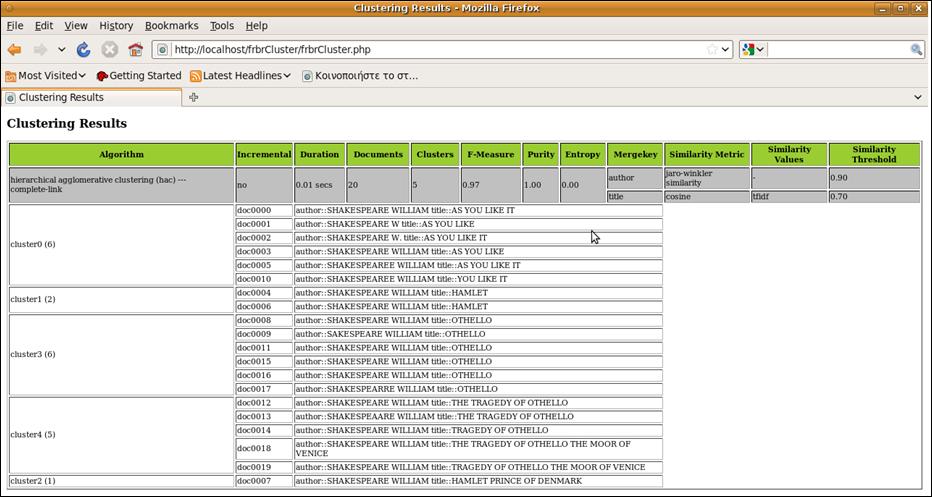
6. An Example
Frbr-keys file
|
author SHAKESPEARE WILLIAM title AS YOU LIKE IT author SHAKESPEARE W title AS YOU LIKE author SHAKESPEARE W. title AS YOU LIKE IT author SHAKESPEARE WILLIAM title AS YOU LIKE author SHAKESPEARE WILLIAM title HAMLET author SHAKESPEAREE WILLIAM title AS YOU LIKE IT author SHAKESPEARE WILLIAM title HAMLET author SHAKESPEARE WILLIAM title HAMLET PRINCE OF DENMARK author SHAKESPEARE WILLIAM title OTHELLO author SAKESPEARE WILLIAM title OTHELLO author SHAKESPEAREE WILLIAM title YOU LIKE IT author SHAKESPEARE WILLIAM title OTHELLO author SHAKESPEARE WILLIAM title THE TRAGEDY OF OTHELLO author SHAKESPEAARE WILLIAM title THE TRAGEDY OF OTHELLO author SHAKESPEARE WILLIAM title TRAGEDY OF OTHELLO author SHAKESPEARE WILLIAM title OTHELLO author SHAKESPEARE WILLIAM title OTHELLO author SHAKESPEARRE WILLIAM title OTHELLO author SHAKESPEARE WILLIAM title THE TRAGEDY OF OTHELLO THE MOOR OF VENICE author SHAKESPEARE WILLIAM title TRAGEDY OF OTHELLO THE MOOR OF VENICE |
Frbr-classes (works) file
|
1 2 3 4 6 11 5 7 8 9 10 12 16 17 18 13 14 15 19 20 |
Configuration file
|
<?xml version="1.0" encoding="UTF-8"?>
<psclustering>
<clustering_algorithm name="hac" check_all="no" inter_cluster_sim="complete-link" incremental="no" step="20" print_step_results="no" />
<mergekeys>
<mergekey name="author"> <similarity_computation doc_vector_values="tfidf" similarity_method="jaro-winkler" similarity_threshold="0.90" similarity_threshold_upper="0" similarity_threshold_step="0"/> </mergekey>
<mergekey name="title"> <similarity_computation doc_vector_values="tfidf" similarity_method="cosine" similarity_threshold="0.70" similarity_threshold_upper="0" similarity_threshold_step="0"/> </mergekey>
</mergekeys>
</psclustering> |
Results
|
|